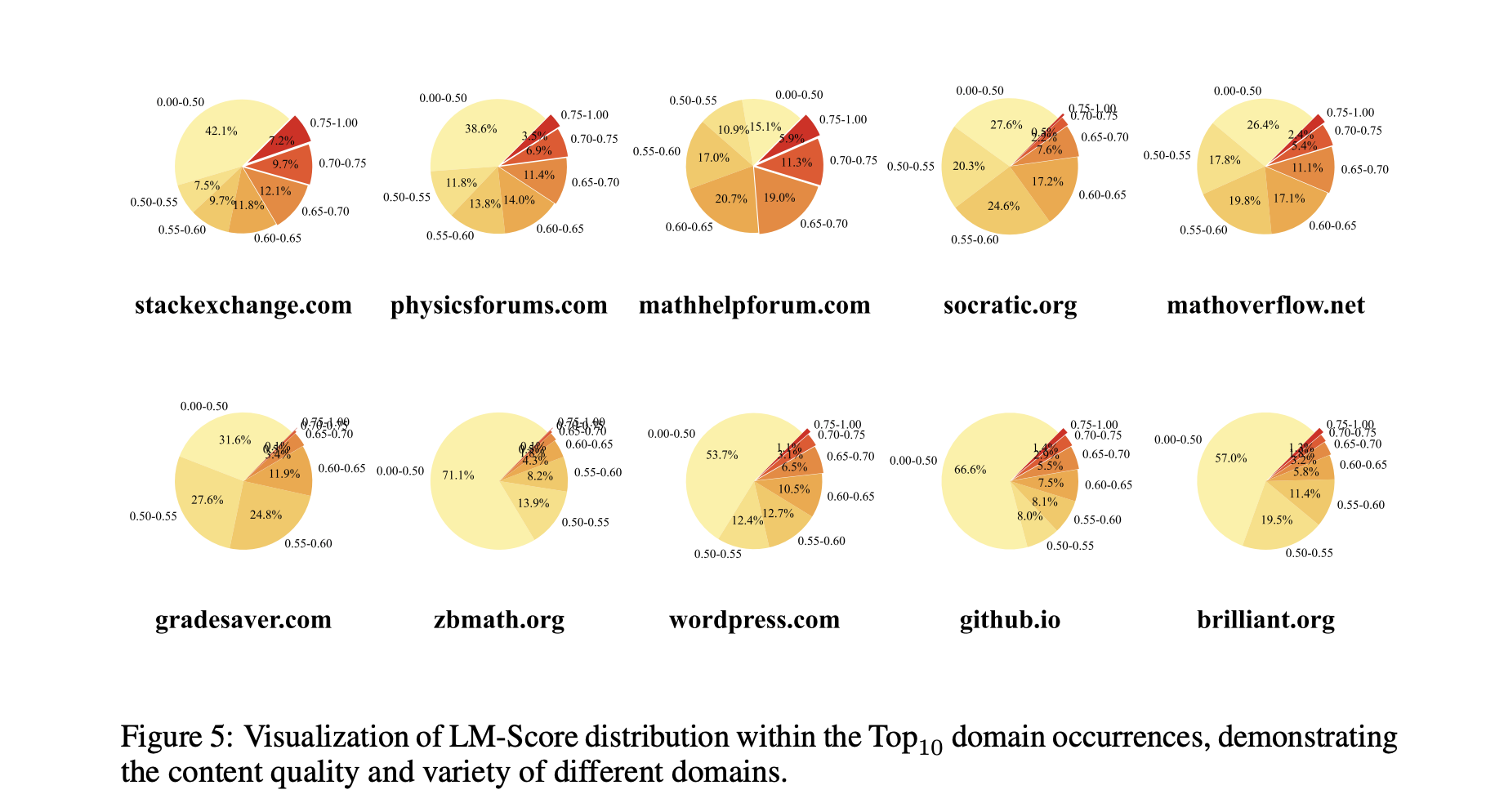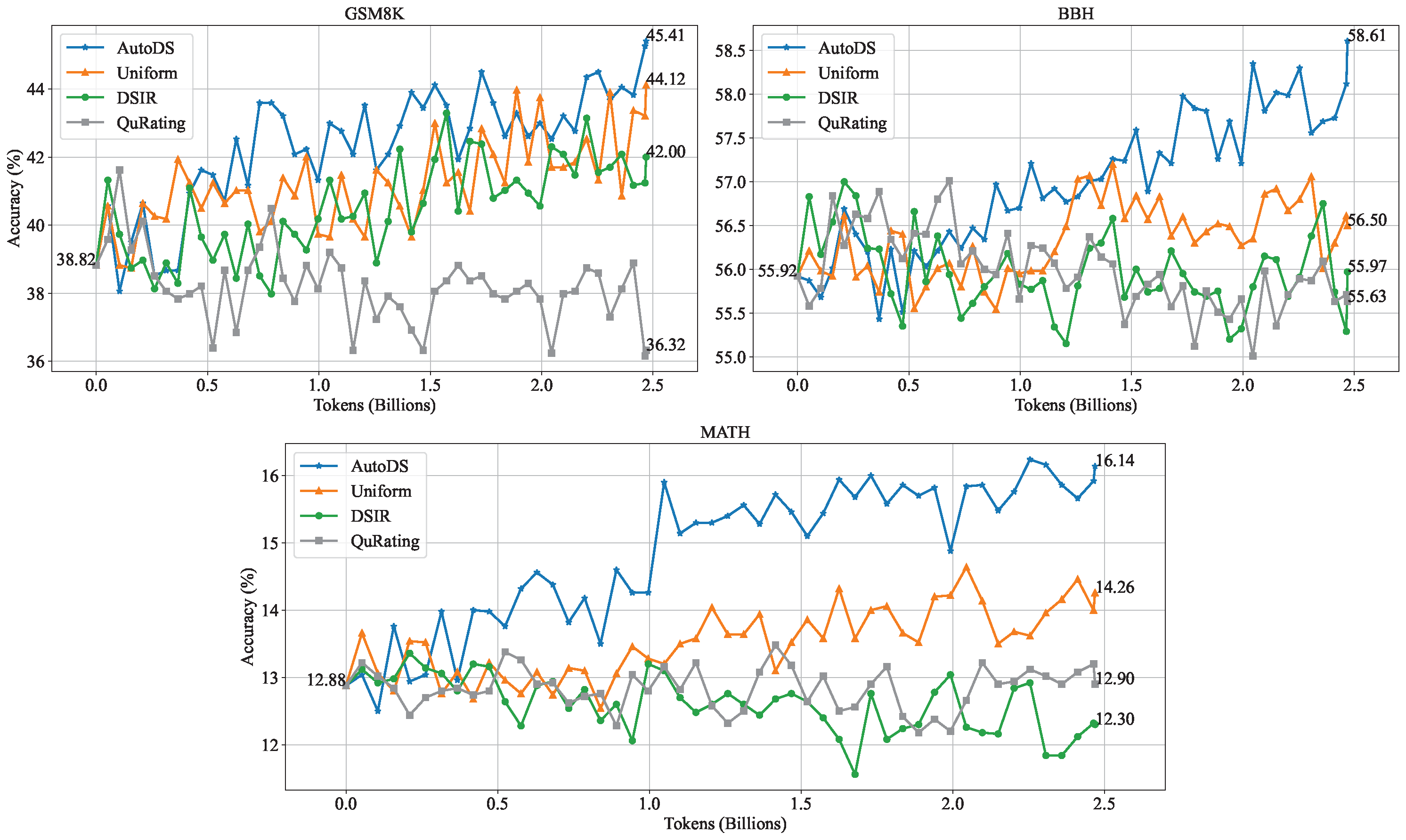
We present Autonomous Data Selection (AutoDS), a method that leverages base language models themselves as zero-shot "generative classifiers" to automatically curate high-quality mathematical texts. Unlike prior approaches that require human annotations or training a dedicated data filter, AutoDS relies solely on a model's logits to determine whether a given passage is mathematically informative and educational. By integrating AutoDS into a continual pretraining pipeline, we substantially boost downstream performance on challenging math benchmarks (MATH, GSM8K, and BBH) while using far fewer tokens than previous methods. Empirically, our approach achieves roughly a twofold improvement in pretraining token efficiency over strong baselines, underscoring the potential of self-directed data selection in enhancing mathematical reasoning. We release our curated AutoMathText dataset to facilitate future research in automated domain-specific data curation. The AutoMathText dataset is available at this link.
Please cite the paper and star this repo if you use AutoMathText or AutoDS and find it interesting/useful, thanks!
@article{zhang2025autonomous,
title={Autonomous Data Selection with Zero-shot Generative Classifiers for Mathematical Texts},
author={Zhang, Yifan and Luo, Yifan and Yuan, Yang and Yao, Andrew C},
journal={The 63rd Annual Meeting of the Association for Computational Linguistics (ACL 2025 Findings)},
year={2025}